
Introduction
In this post I'd like to introduce some basic details about ElasticSearch. I've been following the development of ES since 2011, when the company I used to work for was migrating from Solr to ES. In the last year I stopped using it completely and right now it's time to do my homework and catch up with the current status of ES. The 2.0.0 version has just been released and it's a good time to revisit this excellent tool.
I'd like to write about some of the use cases for ElasticSearch, it's main concepts and some considerations on where it's a good/bad idea to consider using it. Also I'll try to describe some details about how ElasticSearch stores and retrieves documents and how we can extract the best of it. I hope that after that you would be familiarised with some technical stuff of ES and would be able to start applying some of this things in your projects.
What's ElasticSearch?
The first thing to understand about ElasticSearch is: what exactly is ElasticSearch?
ES is a document oriented database. This means that it's all about storing and retrieving documents. In ES all documents are represented in JSON format. It is built on Lucene a information retrieval software that has more than 15 years of experience on full text indexing and searching.
If you have ever used MongoDB probably you'll be familiarised with a JSON storage service. But what makes ES really special is it's information retrieval nature. This combination of storage and querying/aggregation services makes ES really special and distant from the "document storage only" tools.
Given it's nature another important thing to know is when to use ElasticSearch. It won't be a good idea to switching your SQL databases for ES. They have different purposes and each one has it's benefits and drawbacks. Some of the use cases where ES excels are:
- Searching for pure text (textual search)
- Searching text and structured data (product search by name + properties)
- Data aggregation
- Geo Search
- JSON document storage
Basic Concepts
Let's take a look at the main concepts of ElasticSearch:
- Cluster: A set of Nodes (servers) that holds all the data.
- Node: A singel server that holds some data and participate on the cluster's indexing and querying.
- Index: Forget SQL Indexes. Each ES Index is a set of Documents.
- Shards: A subset of Documents of an Index. An Index can be divided in many shards.
- Type: A definition of the schema of a Document inside of an Index (a Index can have more than one type assigned).
- Document: A JSON object with some data. It's the basic information unit in ES.
For more details about the basic concepts of Elastic Search take a look in this part of the documentation.
Good and Bad of ElasticSearch
First of all I'd like to talk about some of the reasons to consider using ES on your system.
The first thing is speed. ES is has very good performance. As I said before it's built on top of Lucene and the capability of spanning queries in parallel inside a cluster performs very well (more on that parallels in a latter post).
Other nice thing about ElasticSearch is that for it's queries the result can be ordered by Relevance. By default ES uses the TF/IDF similarity algorithm to calculate the relevance. If you don't know what is relevance take a look at this page in the ES documentation.
Last but not least, ES can be very useful to generate aggregate statistics and have very versatile Search API that can meet you requirements with little effort.
But there are some bad things too. There is no silver bullet! ElasticSearch is very powerful in searching and aggregating data, but if you have an environment of extremely writing operations, maybe ES won't be your best option (but you can at least give it a try, it doesn't do that bad).
Also, it doesn't have any kind of transactional operations. But as long as you don't rely on it as your primary data storage you should be fine.
Indexing and Searching
Rest API
ElasticSearch uses a Rest API for searching and storing documents. Below there is an example of a indexing (storing) a document:
$ curl -XPUT 'http://localhost:9200/blog/post/1' -d '{
"author": "lucas",
"tags": ["java", "web"],
"title": "A Fancy Title",
"context": "A nice post content..."
}'
The http://localhost:9200/ is the address of our ES node. Here we are creating a blog post in the index blog with a type post and an id = 1. Note that it's possible to use a POST instead of a PUT to automatically generate the document id. The document itself is a ordinary Json document.
Now let's take a look at the request to retrieve a document:
$ curl -XGET 'http://localhost:9200/blog/post/_search' -d '{
"query" : {
"term" : { "author" : "lucas" }
}
}'
It's very straightforward to understand what is being queried. A query can be send either by a GET or a POST. The blog defines which indexes we are querying and the post is the document type (it's an optional parameter). The _search are telling the action that we want to execute. The body of the query will determine the type of query and the parameters. In this case we are looking for any documents that the value of field author has the term lucas.
The Document API and the Search API have a lot of details and possibilities, this are just the basics. Take a look in the ES documentation to learn more about these two.
Before diving into details about indexing a document. Let's discuss about how ES executes the query.
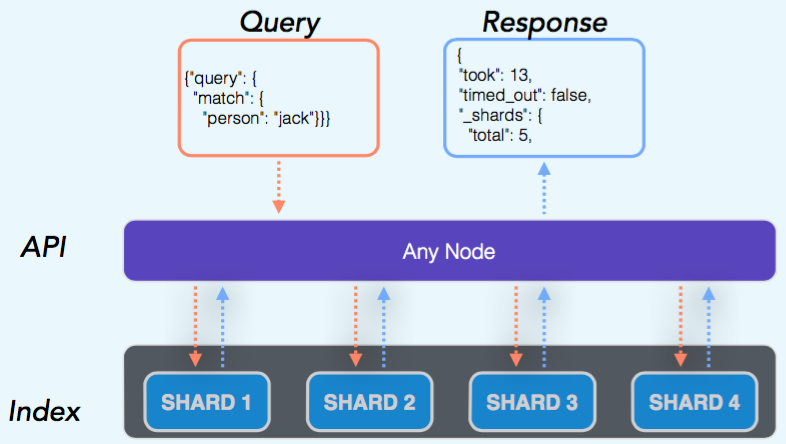
(image taken from the slides of the presentation An ElasticSearch Crash Course, by Andrew Cholakian)
When you send a query to your ES cluster, the query will hit one of the nodes (in a round robin basis) and then it figures out which shards should be queried. Then the "query coordinator" node sends the query to each one of those shards to execute the query in parallel. After each node answers the query with the partial result, the node merges the result and send it back to the user. One of the things that makes ES very fast in querying documents is that by default it already execute queries in parallel (traversing the shards).
Indexing
There are other details that allows ES to be very effective in searching the documents. When storing a document in ES it creates some internal data structures that makes the query perform better. I'll talk about some basic details of ES indexing techniques.
Every document that are sent to ES to be stored go through a hashing algorithm and then are sent to a shard. ES tries to distribute the documents evenly across the shards of the index.
When storing the document ES creates an inverted index mapping the terms of the terms present on the document to the document itself.
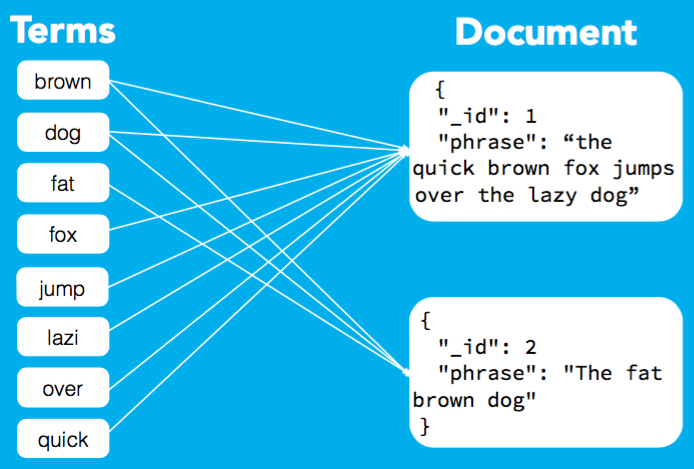
(image taken from the slides of the presentation An ElasticSearch Crash Course, by Andrew Cholakian)
Using the inverted index it's possible to search through the terms as a binary tree (using the alphabetical order) which reduces the time of the search.
Another important thing when storing documents is deciding the best way to store them enhancing the query speed. When designing solutions using ElasticSearch the most important thing to think about when storing documents is: how would I like to query for this document?. This "query first" approach facilitates the use of all ES indexing possibilities to make our queries incredible fast. That's when the Analysers of ES are very important.
Analysis
Analysis is a text transformation that takes as input a chunk of text and outputs terms (tokens). One of the best features of ES is that it comes with a lot of built-in analysers.
For example imagine a function that takes each word in a text block and returns the stemmed form of each word. Or a function that takes a text and remove all the stop words of it. Depending on what you need you can use one or more analysers to transform the original text.
In ES the analysers are useful on helping us building good indexes (database indexes) and speed up the search through our documents. Take a look in the ES Analysers documentation to see some examples of the analysers that come with ES.
Querying
Another powerful feature of ElasticSearch are all of the queries types it provides out-of-the-box. There are nearly 40 query types and probably one of them will be perfect for what you need.
We have the phrase queries for textual search, geo queries based on coordinates, numeric range queries that can be very useful for aggregate data and a lot more. There are a lot to see about ES queries don't forget to read the documentation about them.
Conclusion
It's very difficult to write about ElasticSearch. At the same time it is simple to use and understand, there is a lot of features to talk about. Sometimes you have more than a way on indexing some documents or querying them. I believe that only with experience using ES you can become better and take most of it.
This doesn't mean that you shouldn't try using it. One of the benefits of ES is that it is very easy to install and, for many use cases, it won't be your primary datasource, so you can be less worried on trying it.
As I said earlier, it's important to know the things that ES are good and the this that it's bad. A vast majority of people that I heard complaining about ES were using it in a way it wasn't meant to be.
ElasticSearch isn't quite new but is evolving fast. They are evolving and adding new good stuff on every release. But it's core are very consistent and the fact that it's build on top of Lucene give us more confidence to use it.
That's it! I'm very grateful for writing this post because it helped me refreshing some concepts of ES and also taking a look onto the new features. I hope that in the near future I'd have the opportunity to use these features in something useful. See ya!